DeepMind、“知らない空間”の情報を生成できるAIを開発 「想像するAI」の萌芽か
トッププロ囲碁棋士に勝利した囲碁ソフト『AlphaGo』を開発して一躍有名になったGoogle傘下のAI開発会社DeepMindが、従来よりヒトのように世界を認識するAIを開発したことを発表した。このAIは、ヒトにしかできないと思われていたあることができるのだ。
部分から全体を知れないAI
近年になって急速に進化して社会への実装が進んでいるAIが抱えている問題のひとつに、学習プロセスの煩雑さがあげられる。例えば、画像のなかにネコが写っているかどうか判定するAIを開発する場合、大量のネコが写った画像を用意する必要がある。
AIに空間の状況把握をさせようとすると、さらに複雑な判断能力が必要になる。部屋のなかにあるイスやテーブルを認識しければならないし、部屋全体の構造もわからないとならない。しかも、リアルの空間では1ヶ所から見える情報は限らている。ヒトであれば、テーブルの脚が3本見えたら、例え4本目の脚が見なくてもあるだろうと考える。こうしたヒトならば当たり前に行う推測が、実のところ、AIは苦手としている。4本の脚を認識してはじめて、AIはそれがテーブルであることを判断するのであって、3本脚のオブジェクトは(3本脚のテーブルを学習していなければ)テーブルとは認識しない。
このようにAIは、ヒトならば当たり前に行う「部分から全体」を推測する認知能力が欠けているのだ。
限られた情報から世界を知るAI
DeepMindは、15日、空間把握において部分から全体を推測できるAIを開発したことを伝えるブログ記事を公開した。GQN(Generative Query Network:質問生成ネットワーク)と命名されたAIは、簡単に言えば、ある空間の全体を知るために欠けている部分に関する情報を「想像」して補うことができるのだ。
GQNは、表現ネットワークと生成ネットワークというふたつの機能から構成されている。表現ネットワークは、AIに設定された視野の範囲内の空間情報を取得し、状況を認識する。表現ネットワークは、ちょうどヒトが空間を一挙に全方位から認識できなように、空間に関する部分的な情報しか認識できない。対して生成ネットワークは、表現ネットワークが認識した空間情報をもとにして、まだ認識していない空間に関する情報を生成する。言ってみれば、まだ知らない空間について「想像」するのである。そして、表現ネットワークが認識した空間情報と生成ネットワークが生成した空間情報を総合することによって、空間の全体像を認識するのだ。
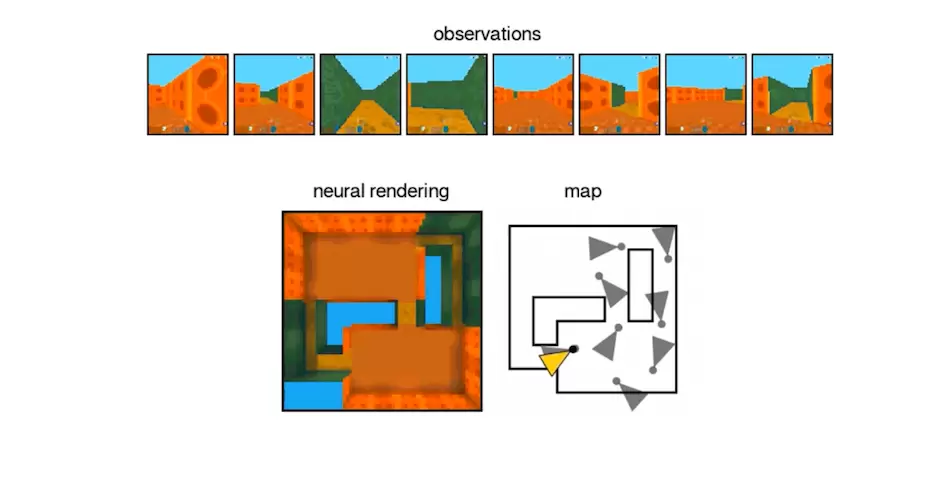
以上のような空間認識は、GQNが迷路を認識するプロセスを解説すると分かりやすい。例えば、GQNを実装したロボットを迷路の真ん中に置いてみたとしよう。このロボットは、迷路のなかを動き回り部分的な空間情報を取得する。この部分的な情報を使って、まだ見ていない空間についても生成して、いつしか迷路全体を把握するのだ(トップ画像を参照)。
「想像」するAIの萌芽
クイーンズランド大学でロボット工学の教鞭をとっており(GQN開発には関わっていないが)DeepMindと協同研究を行っているMichael Milford教授は、GQNは自律自動車や家庭用ロボットに応用できることを指摘している。GQNを実装すれば、自律自動車は正確な地図がない場所であって走行でき、お掃除ロボットもより少ない情報処理で部屋の構造を認識できるようになるだろう。
GQNの開発を率いたDeepMindの研究員Danilo Rezende氏は、このAIが従来では答えられなかった種類の質問に対応できる点を強調している。従来型のAIは、「画像のなかにヒトはいるかどうか」といったYes/Noで応えられる質問は適切に処理できた。その一方で、「もしこの画像を違う角度から見たらどうなるか」というようなIFを含む質問に対しては答えられなかった。GQNはこうしたIFに答えることができるのだ。そして、「もし~だったら、どうなるか」と考えることは、紛れもなく想像力を働かす第一歩である。それゆえ、きわめて原初的ではあるがGQNは「想像力があるAI」と言えるのではなかろうか。
ちなみにGQNを発表したブログ記事によると、将来的にはVR/ARアプリにも応用することを考えている、とのこと。オープンワールドのVRRPGに登場するNPCにGQNを実装したら、より「ヒトらしく」動くようになるかもしれない。
AIは、かつてはヒトにしかできないと思われたことを着実に実行可能としている。こうしたAIの進化をヒトの対する脅威と考えるよりは、より広い範囲でヒトとAIが協働できるチャンスととらえたほうがよりクールな未来に近づけるだろう。
参照記事
ABC「Who needs humans? Google's DeepMind algorithm can teach itself to see」
トップ画像出典:DeepMind「Neural scene representation and rendering」
■吉本幸記
テクノロジー系記事を執筆するフリーライター。VR/AR、AI関連の記事の執筆経験があるほか、テック系企業の動向を考察する記事も執筆している。Twitter:@kohkiyoshi



















